- Katılım
- 2 Ocak 2026
- Mesajlar
- 38
- Tepkime puanı
- 46
- Puan
- 18
Merhaba arkadaşlar, bugün karmaşık görsel veriler içinden coğrafi ve mimari ayrıntıları ayırt eden yüksek doğruluk oranına sahip bir derin öğrenme projesini anlatacağım. Bu projede hedefimiz 6 farklı kategorideki (Bina, Orman, Buzul, Dağ, Deniz, Sokak) görüntüleri insan gözüne yakın bir hassasiyetle sınıflandırmaktır. Bu projemde kullandıklarımla başlayalım.
Veri Seti: Intel Image Classification
Böyle projelerde kullanılan veri setleri modelin "dünyayı tanıması" için gereken bilgiyi sağlıyor.
Kapsam: ~25.000 Eğitim, 3.000 Test görüntüsü.
Sınıflar: Buildings, Forest, Glacier, Mountain, Sea, Street.
Format: 150x150 Piksel, RGB.
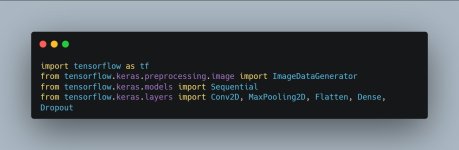
1. Hazırlık ve Kütüphane Seçimi
İlk adım, sistemin beynini (TensorFlow) ve veri işleme araçlarını projemize dahil edip projemiz için başlangıcı yapmak.
Ne işe yarar? Sequential modelin katmanlarını üst üste dizmemizi sağlar. Conv2D ise görüntünün içindeki detayları yakalayan "gözümüzdür".
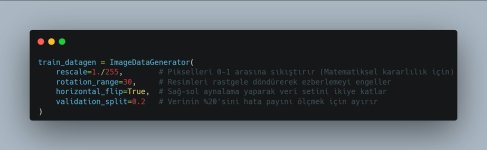
2. Veri Ön İşleme (Preprocessing) ve Augmentation
Görüntüleri olduğu gibi modele veremeyiz. Onları hem modelin anlayacağı şekle getirlmeli hem de modeli daha zeki yapmak için çeşitlendirmeliyiz.
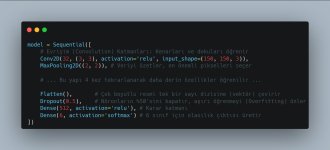
3. Model Mimarisinin İnşası (CNN Architecture)
Burada "Derin" öğrenmenin katmanlarını oluşturuyoruz.
4. Model Eğitimi (Training)
Modeli eğittiğimiz model.fit aşaması, projenin en çok işlem gücü gerektiren kısmıdır.
Accuracy (Doğruluk): Eğitim boyunca %43'ten başlayıp %79.3 seviyelerine kadar çıktı.
Validation: Doğrulama setindeki başarının da eğitim setiyle doğru orantılı olarak gitmesi, modelin sadece ezberlemediğini, gerçekten öğrendiğini gösterir.
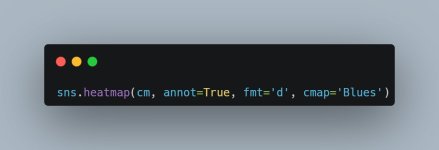
5. Karmaşıklık Matrisi (Confusion Matrix) Analizi
6. Canlı Demo: Tahmin Yapma
Kodun son kısmında, 23273.jpg isimli bir sokak fotoğrafını modele sorduk:
Girdi: Rastgele bir sokak fotoğrafı.
Sonuç: Predicted Class: street
Güven Oranı: %90.16
Model, resimdeki binaları, kaldırımları ve yol dokusunu birleştirerek bunun bir "sokak" olduğuna %90 emin bir şekilde karar verdi.
Özet
Bu proje; veriyi okuma, katmanları tasarlama, hata payını en düşüğe indirme ve sonunda tahmin yürütme adımlarıyla bir uçtan uca derin öğrenme hattı (Pipeline) örneğidir.
Bu kod bloğu, modelin daha önce hiç görmediği bir görüntüyü alıp, onu işleyerek bir tahmine dönüştürme sürecini gösteriyor.
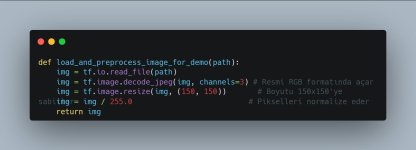
1. Veriyi Hazırlama (Preprocessing for Demo)
Model eğitilirken resimler nasıl işlendiyse, tekil tahmin yapılırken de aynı işlemlerden geçmelidir. Aksi halde model resmi tanıyamaz.
Kritik Nokta: 150, 150 boyutu, modelin giriş katmanıyla (input_shape) birebir aynı olmalıdır. Yoksa çakışma yaşanabilir.
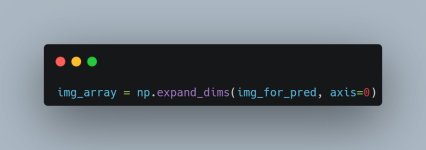
2. Boyut Genişletme (Expanding Dimensions)
Yeni başlayanların en çok hata yaptığı yer burasıdır.
Neden Yapıyoruz?
Modelimiz eğitim sırasında yığın halinde veri almaya alışkındır. Yani model (150, 150, 3) değil, (1, 150, 150, 3) şeklinde bir giriş bekler. Buradaki 1, "şu an sadece 1 tane resim gönderiyorum" demektir.
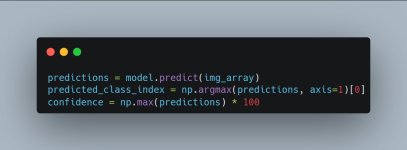
3. Tahmin ve Olasılık Hesabı
Modelin beynine resmi gönderiyoruz ve bize 6 sınıfa ait olasılık puanlarını veriyor.
np.argmax: Modelin ürettiği 6 olasılık içinden en yüksek olanın indeksini seçer (Örn: 5. indeks -> Street).
confidence: Modelin o tahminden ne kadar emin olduğunu yüzdeye çevirir.
4. Sonucu İnsan Dilinde Görselleştirme
Bilgisayarın 5 dediği sonucu, bizim için Street (Sokak) yazısına ve görseline çeviriyoruz.
Çıktı: Ekrana resim gelir ve üstünde modelin tahmini ile ne kadar güvendiği (Örn: %90.16) yazar.
Bu kod parçası, bir yapay zeka modelinin "üretim ortamında" (Production) nasıl çalıştığının en temel örneğidir. Bir mobil uygulama veya web sitesi üzerinden fotoğraf yüklediğinde, arka planda tam olarak bu işlemler döner: Yükle -> Boyutlandır -> Normalize Et -> Tahmin Et -> Sonucu Göster.
Veri Seti: Intel Image Classification
Böyle projelerde kullanılan veri setleri modelin "dünyayı tanıması" için gereken bilgiyi sağlıyor.
Kapsam: ~25.000 Eğitim, 3.000 Test görüntüsü.
Sınıflar: Buildings, Forest, Glacier, Mountain, Sea, Street.
Format: 150x150 Piksel, RGB.
1. Hazırlık ve Kütüphane Seçimi
İlk adım, sistemin beynini (TensorFlow) ve veri işleme araçlarını projemize dahil edip projemiz için başlangıcı yapmak.
Ne işe yarar? Sequential modelin katmanlarını üst üste dizmemizi sağlar. Conv2D ise görüntünün içindeki detayları yakalayan "gözümüzdür".
2. Veri Ön İşleme (Preprocessing) ve Augmentation
Görüntüleri olduğu gibi modele veremeyiz. Onları hem modelin anlayacağı şekle getirlmeli hem de modeli daha zeki yapmak için çeşitlendirmeliyiz.
3. Model Mimarisinin İnşası (CNN Architecture)
Burada "Derin" öğrenmenin katmanlarını oluşturuyoruz.
4. Model Eğitimi (Training)
Modeli eğittiğimiz model.fit aşaması, projenin en çok işlem gücü gerektiren kısmıdır.
Accuracy (Doğruluk): Eğitim boyunca %43'ten başlayıp %79.3 seviyelerine kadar çıktı.
Validation: Doğrulama setindeki başarının da eğitim setiyle doğru orantılı olarak gitmesi, modelin sadece ezberlemediğini, gerçekten öğrendiğini gösterir.
5. Karmaşıklık Matrisi (Confusion Matrix) Analizi
6. Canlı Demo: Tahmin Yapma
Kodun son kısmında, 23273.jpg isimli bir sokak fotoğrafını modele sorduk:
Girdi: Rastgele bir sokak fotoğrafı.
Sonuç: Predicted Class: street
Güven Oranı: %90.16
Model, resimdeki binaları, kaldırımları ve yol dokusunu birleştirerek bunun bir "sokak" olduğuna %90 emin bir şekilde karar verdi.
Özet
Bu proje; veriyi okuma, katmanları tasarlama, hata payını en düşüğe indirme ve sonunda tahmin yürütme adımlarıyla bir uçtan uca derin öğrenme hattı (Pipeline) örneğidir.
Bu kod bloğu, modelin daha önce hiç görmediği bir görüntüyü alıp, onu işleyerek bir tahmine dönüştürme sürecini gösteriyor.
1. Veriyi Hazırlama (Preprocessing for Demo)
Model eğitilirken resimler nasıl işlendiyse, tekil tahmin yapılırken de aynı işlemlerden geçmelidir. Aksi halde model resmi tanıyamaz.
Kritik Nokta: 150, 150 boyutu, modelin giriş katmanıyla (input_shape) birebir aynı olmalıdır. Yoksa çakışma yaşanabilir.
2. Boyut Genişletme (Expanding Dimensions)
Yeni başlayanların en çok hata yaptığı yer burasıdır.
Neden Yapıyoruz?
Modelimiz eğitim sırasında yığın halinde veri almaya alışkındır. Yani model (150, 150, 3) değil, (1, 150, 150, 3) şeklinde bir giriş bekler. Buradaki 1, "şu an sadece 1 tane resim gönderiyorum" demektir.
3. Tahmin ve Olasılık Hesabı
Modelin beynine resmi gönderiyoruz ve bize 6 sınıfa ait olasılık puanlarını veriyor.
np.argmax: Modelin ürettiği 6 olasılık içinden en yüksek olanın indeksini seçer (Örn: 5. indeks -> Street).
confidence: Modelin o tahminden ne kadar emin olduğunu yüzdeye çevirir.
4. Sonucu İnsan Dilinde Görselleştirme
Bilgisayarın 5 dediği sonucu, bizim için Street (Sokak) yazısına ve görseline çeviriyoruz.
Çıktı: Ekrana resim gelir ve üstünde modelin tahmini ile ne kadar güvendiği (Örn: %90.16) yazar.
Bu kod parçası, bir yapay zeka modelinin "üretim ortamında" (Production) nasıl çalıştığının en temel örneğidir. Bir mobil uygulama veya web sitesi üzerinden fotoğraf yüklediğinde, arka planda tam olarak bu işlemler döner: Yükle -> Boyutlandır -> Normalize Et -> Tahmin Et -> Sonucu Göster.
Ekli dosyalar
-
 carbon.jpg71,9 KB · Görüntüleme: 19
carbon.jpg71,9 KB · Görüntüleme: 19 -
 carbon (1).jpg79,3 KB · Görüntüleme: 19
carbon (1).jpg79,3 KB · Görüntüleme: 19 -
 carbon (2).jpg109,7 KB · Görüntüleme: 19
carbon (2).jpg109,7 KB · Görüntüleme: 19 -
 carbon (3).jpg23,3 KB · Görüntüleme: 13
carbon (3).jpg23,3 KB · Görüntüleme: 13 -
 1767545499306.jpg53,5 KB · Görüntüleme: 12
1767545499306.jpg53,5 KB · Görüntüleme: 12 -
 carbon (4).jpg126,2 KB · Görüntüleme: 11
carbon (4).jpg126,2 KB · Görüntüleme: 11 -
 carbon (5).jpg71 KB · Görüntüleme: 11
carbon (5).jpg71 KB · Görüntüleme: 11 -
 carbon (6).jpg23,3 KB · Görüntüleme: 10
carbon (6).jpg23,3 KB · Görüntüleme: 10 -
 carbon (7).jpg47,1 KB · Görüntüleme: 10
carbon (7).jpg47,1 KB · Görüntüleme: 10 -
 carbon (9).jpg47,5 KB · Görüntüleme: 9
carbon (9).jpg47,5 KB · Görüntüleme: 9